
Looking for a way to speed up the generation of accurate captions? Interested in AI vocabulary training?
Earlier, IBM introduced Watson Captioning to generate captions for videos using speech to text. These captions could then be edited for accuracy, or to adhere to personal preferences. Those capabilities are being expanded with the addition of the ability for Watson to learn based on those edits or to be taught. As a result, this can speed up the process of accurate caption generation through removing previously repeated tasks.
Note that this feature for Watson to learn based on edits or to be manually taught is currently only available from the stand alone Watson Captioning solution. It is not currently available for Streaming Manager or Streaming Manager for Enterprise, although will be coming to those in the future.
- How Watson learns: AI vocabulary and context
- The advantage of training Watson
- Self-learning: automatically training Watson
- Manually adding words to Watson’s vocabulary
- Tips for training Watson
How Watson learns: AI vocabulary and context
When it comes to teaching Watson for the process of caption generation, two concepts come into play. The first is enhancing vocabulary. This is the process of teaching Watson terms, names or abbreviations it’s not already familiar with. For example, if your company invented a product or technology called the RuskBeam this new term could be taught to Watson.
The other way that Watson learns is through context, or corpus. This aids in teaching when to use a specific word based on the surrounding context. When different words or phrases sound the same, like “ate” versus “eight” or “genes” versus “jeans”, it’s up to context to determine when one is used versus the other. For example, when sandwich is used in combination with a word that sounds like “ate” it’s less likely to be talking about numbers, or if clothing store is used in combination with a word that sounds like “jeans” it’s less likely to be talking about genetics. Through teaching Watson different scenarios, it starts to learn when one should be used over the other.
The advantage of training Watson
For content owners, the key advantage of training Watson is the ability to generate increasingly accurate captions out of the gate. Consequently, improving the initial accuracy and reducing the amount of time required to edit captions. It leans on the idea that concepts and things will repeat across content from the same company or content owner. This can range from the name of a musical act to even personalities or company names. By training Watson on these terms, it can remove the hassle of having to repeatedly correct them from the speech to text process, saving time.
It should be noted that training Watson does not “improve” Watson for other people. For example, if Watson is taught to correctly transcribe a sports player’s name by a company, another company using Watson Captioning will not automatically gain this benefit if the player’s name comes up. Training Watson just benefits the company using Watson Captioning directly.
Now training Watson works in two different ways, one of them is through self-learning and the other a manual approach.
Self-learning: automatically training Watson
As content owners add and edit more assets in Watson Captioning, Watson learns from this process. This can include names, industry terms and more as part of its vocabulary. For example, if a content owner edits the first name of baseball player “Yoenis Céspedes”, actually pronounced yo-EH-nee, then Watson will pick up on this.
 In terms of workflow, the process involves first editing generated captions. Afterwards, the captions have to be marked as ready, signaling they are completed, to start the training process. From here, content owners can click an “Improve Watson” button from the Videos page. This will populate a list of the names, terms and corrections that Watson could be trained on. The list can be reviewed, with specific terms deleted or edited. Once the list is acceptable, clicking a “Train Watson” button will train the artificial intelligence on these terms.
In terms of workflow, the process involves first editing generated captions. Afterwards, the captions have to be marked as ready, signaling they are completed, to start the training process. From here, content owners can click an “Improve Watson” button from the Videos page. This will populate a list of the names, terms and corrections that Watson could be trained on. The list can be reviewed, with specific terms deleted or edited. Once the list is acceptable, clicking a “Train Watson” button will train the artificial intelligence on these terms.
Naturally, not every edit is a new term to be learned. Aspects that help them to be included are repetition of edits and also proper nouns. In the case of the latter, names and other proper nouns are given greater emphasis as a new word to learn, to the point where editing it a single time can cause it to be added to the list for approval. So capitalizing a word will have a greater likelihood of being suggested as an addition, excluding if that word starts a new sentence and would be capitalized anyway.
Note that the list of possible additions focuses on vocabulary, although behind the scenes it’s also learning from context as well from these edits even if it’s not visualized in the list. For example, changing “the grease” to “degrees” wouldn’t be suggested as a vocabulary addition, although it would search for context based on your edits. Like if the passage was “it was 82 degrees Celsius” it might learn that the appearance of a number or the term Celsius are indicators to use “degrees”.
Manually adding words to Watson’s vocabulary
For the manual approach, this involves clicking the “Improve Watson” button in the upper right on the Videos page. This will launch a lightbox where you can click an “Add new” button. From here one can choose what happens when Watson hears something and what it should actually display as. For example, one could state that something which sounds like “e commerce” should display as “eCommerce” in the captions that are generated.
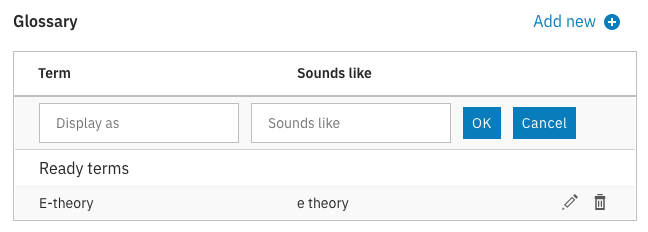
Note that training Watson manually in this way does not impact already edited or already generated captions. It will only factor into new content that is uploaded and features phrases that match this teaching.
Tips for training Watson
There are a variety of different scenarios where the ability to teach Watson can speed up the caption process. It can also, though, be used to create captions that are closer to the preferred end result as well. Below are a few tips to use with this new feature:
- Company / institute name
There can be a lot of scenarios where Watson is transcribing words correctly but not with proper capitalization. For example, “San Francisco museum of modern art” would technically be correct if not for the fact it was a name and therefore lacks proper capitalization. So one trick can be to teach Watson on these specific names. So using the above example, you can teach Watson that when it hears “San Francisco museum of modern art” it should actually be “San Francisco Museum of Modern Art”. The same can apply for your own company or products to make sure they have proper capitalization out of the gate, and could be loaded in before starting to upload a library of content. - And vs ampersand
Sometimes an ampersand can be preferred over writing out “and”. A great example of this can be “Q&A” versus “Q and A”. As a result, Watson can be taught when an ampersand would be preferable. - Take advantage of the self-learning capabilities
While you can manually teach Watson, and have this work in tandem with self-learning, often times an ideal strategy is to focus primarily on the self-learning capabilities. This will dig up real world scenarios of things for Watson to be trained on. It also removes the guess work of trying to think through what a term might sound like versus discovering what it actually sounds like.
Summary
Watson Captioning is built around the ideal of simplifying the caption process for video assets. In particular, reducing the amount of time and manpower that needs to be devoted to producing accurate closed captions. Through the ability to train Watson and improve accuracy “out of the gate”, content owners can reduce editing time, decreasing the turn around time for audience ready captions for assets.
Looking for more information on Watson Captioning or how AI is transforming the caption process in general? Be sure to check out our Captioning Goes Cognitive: A New Approach to an Old Challenge white paper. This covers virtually all aspects of Watson Captioning, for both how it’s automating what used to be a very time consuming process and enhancing accuracy of captions as well.